
大数据的学习
大数据学习理解前言
为什么学习大数据,第一方面是对编程这方面感兴趣,我希望通过我的逻辑,去实现代码,来创造出价值,然后供我恰饭。世界上最美好的事情是,做自己爱做的事情,并且能够赚到钱,然后可以恰饭,仅此而已。
Hadoop入门学习
Hadoop的思想之源来自于Google的三篇论文:
GFS —> HDFS
Map-Reduce —> MR
BigTable —> HBase。
Hadoop三大发行版本
Hadoop三个发行版本:Apache、Cloudera、Hortonworks
Apache版本最原始(最基础)的版本,对于入门学习最好。
CLoidear在大型互联网企业中用的较多。
Hortonworks文档最好。
Hadoop的优势(4高)
高可靠性:Hadoop底层维护多个数据副本,默认为3个,所以即使Hadoop某个计算元素或者存储出现故障,也不会导致数据丢失。
高扩展性:在集群间分配任务数据,可方便扩展数以千计的节点。
高效性:在MapReduce,Hadoop的并行工作的,以加速任务处理。
高容错性:能够自动将失败的任务重新分配。
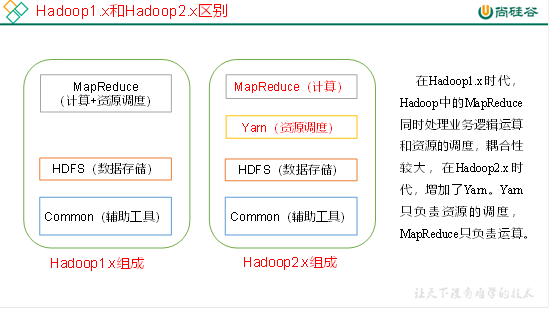
Hadoop1.x和2.x区别
把资源调用又抽象出来,抽出一个yarn
简单说明Hadoop各个模块作用
基础模块:
HDFS:大数据量的处理
MapReduce:大量数据的计算,和业务有关。Map负责拆数据,reduce负责合数据
Yarn:负责资源的调度,分配每个job的执行,所需要的资源
Common:通用的一些程序
拓展模块:
- Hive:对MapReduce封装,可以利用”sql”来运行任务,注意这里的sql是打引号的。后面具体再说!
- Hbase:对hdfs的封装,支持增删改查
Hadoop各个模块说明
HDFS:
- NameNode:存储文件的元数据,如,文件名称,文件目录结构,文件属性(文件大小,所属权限,副本数…),以及每个文件对应的块列表和DataNode,等。所以,理论只有一个。
- DataNode:在本地文件系统存储文件块信息,校验…。所以理论每个服务器都会有一个DataNode
- Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS的元数据。我把他理解成专门辅助NameNode的一个程序,防止NameNode挂掉就GG了,毕竟NameNode存放着文件重要的元数据。
Yarn:
比较复杂的分配资源,详细看下图
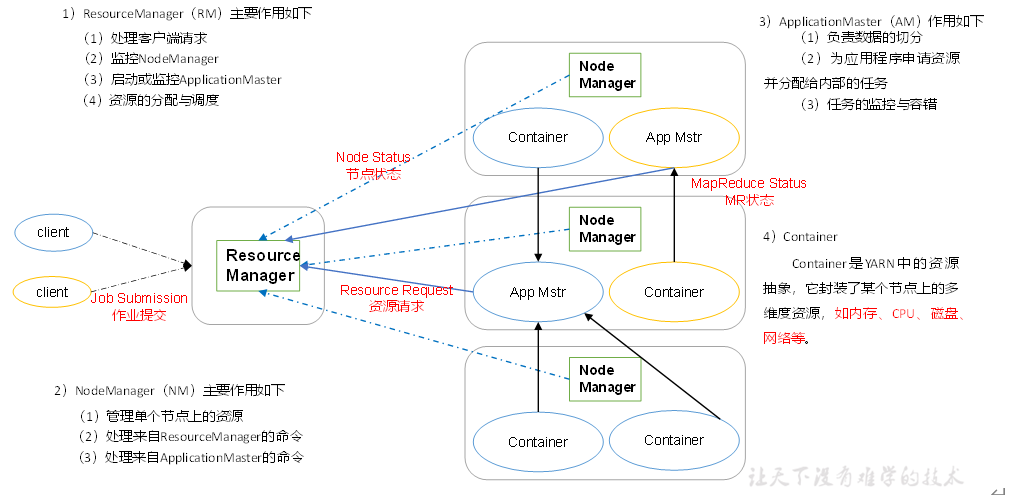 我们尝试去理解下各个模块的意思,可能有错误,但是后续会慢慢的理解。
我们尝试去理解下各个模块的意思,可能有错误,但是后续会慢慢的理解。
- ResourceManager:对Yarn上的模块进行管理分配,是一个leader。所以理论只有一个leader。
- NodeManager:管理本节点的资源,所以,理论一个Hadoop应该会有一个。
- ApplicationMaster:正如名称:Application,对MR的job的申请,和任务的执行做出处理。
- Container:一个资源总的抽象模块
MapReduce:
Map阶段:并行处理数据,主要先Map运行完毕才会执行Reduce。
Reduce阶段:对Map的结果进行汇总
下载Hadoop
下载地址:
1 | https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/ |
下载完解压、配置环境变量。目前Hadoop流行版本就是2.7
注意配置的是bin和sbin
Hadoop本地运行模式
Grep案例
创建测试输入目录
1 | mkdir input |
复制配置文件到输入目录中
1 | cp etc/hadoop/*.xml input |
执行hadoop官方案例
1 | bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+' |
hadoop-mapreduce-examples-2.7.2.jar是hadoop本地的测试案例
grep是执行哪个官方案例,input是输入目录,output是输入目录,后面是正则表达式
最终结果:
1 | 1 dfsadmin |
WordCount案例
创建测试目录
1 | mkdir wcinput |
进入测试目录,创建文件
1 | touch wc.input |
在文件里写入内容,这里我用的是自己的日志文件,就不放出来了,然后执行命令
1 | hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcInput wcoutput |
最终结果就是计算出所有英文出现的次数,这里就不放出结果了。
Hadoop伪分布式模式运行
配置文件+启动hdfs
需要修改3个配置文件。
获取当前java路径,配置进etc/hadoop/hadoop-env.sh脚本里
1 | # The java implementation to use. |
配置nameNode地址和hadoop产生文件地址,在etc/hadoop/core-site.xml里
1 | <!-- 指定HDFS中NameNode的地址 --> |
配置副本数,etc/hadoop/hdfs-site.xml
1 | <!-- 指定HDFS副本的数量 --> |
格式化nameNode
1 | hdfs namenode -format |
启动namenode
1 | sbin/hadoop-daemon.sh start namenode |
启动datanode
1 | sbin/hadoop-daemon.sh start datanode |
jsp查看进程看是否启动成功,然后访问页面,注意关闭防火墙
1 | ip:50070 |
基础操作命令
核心操作文件命令,前缀是hdfs dfs ….,后面命令和linux差不多
如创建文件夹,在后台页面的Browse Directory可以看到
1 | hdfs dfs -mkdir -p /temp/input |
上传文件
1 | hdfs dfs -put 本地路径 hdfs路径 |
hadoop运行模式下的启动官方案例
其实,和上面的没什么区别,不过路径变为hdfs路径了
1 | jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /temp/input /temp/output |
最终的输出也会在hdfs下面看到。
启动yarn并运行mapReduce
修改配置文件,修改etc/hadoop/yarn-env.sh
1 | # some Java parameters |
修改yarn-site.xml,地址填我们的本地地址
1 | <!-- Reducer获取数据的方式 --> |
配置mapred-env.sh
1 | export JAVA_HOME=/usr/local/jdk1.8.0_231 |
配置mapred-site.xml
1 | <!-- 指定MR运行在YARN上 --> |
启动ResourceManager
1 | sbin/yarn-daemon.sh start resourcemanager |
启动NodeManager
1 | sbin/yarn-daemon.sh start nodemanage |
yarn后台访问地址
1 | ip:8088 |
我们跑一个官方案例,yarn后台是能看到记录的,这里就不上图片了,麻烦。我们还能看到历史运行情况,但是我们需要配置一下文件。
在配置mapred-site,xml增加
1 | <!-- 历史服务器端地址 --> |
启动历史服务器
1 | sbin/mr-jobhistory-daemon.sh start historyserver |
这里直接点击job后面的history就能进到后台页面。我们看到了关于这个任务的基本信息。但是想看到详细的日志运行信息,需要在启动一个服务。
配置文件yarn-site.xml增加
1 | <!-- 日志聚集功能使能 --> |
我们需要重启yarn所有服务,先stop
1 | sbin/yarn-daemon.sh stop resourcemanager |
在启动即可。我们重新运行一下官方案例,再点击web端的log就能看到详细的运行日志信息。
Hadoop完全分布模式运行
搭建Linux集群
我们服务器很多,需要改配置的地方很多,不可能一个服务器一个服务器操作,所以需要搭建集群分发脚本,改好的配置文件,一个命令cp过去就行。具体的搭建教程,在我的博客【Linux搭建项目】里。
修改配置文件
我们修改配置文件之前,需要合理的分配资源,就是哪个服务器搭建什么项目,比如namenode,datanode怎么分配。这些是通过配置文件去控制的。所以我们需要知道这些模块的作用,在上面简单复习下。
配置Hadoop核心文件:
vi core-site.xml,我们指定NameNode地址,就像是分布式的注册中心,我们指定了一个注册中心,注册了上去,交给注册中心去管理。
1 | <!-- 指定HDFS中NameNode的地址 --> |
配置Hadoop的env脚本:
vi hadoop-env.sh,一般都是设置JAVA_HOME
小提示:echo ${JAVA_HOME}可以取到设置java环境变量的值
1 | export JAVA_HOME=/opt/module/jdk1.8.0_251 |
配置HDFS:
vi hdfs-site.xml,设置副本数,和辅助的2nn
1 | <!-- 指定Hadoop副本数 --> |
配置Yarn脚本:
vi yarn-env.sh,还是设置JAVA_HOME
1 | export JAVA_HOME=/opt/module/jdk1.8.0_251 |
配置Yarn配置文件:
vi yarn-site.xml,这里设置Reduce获取数据的方式,和yarn的lerder的地址,我们设置一个就好了,这里我们可以发现,为什么NameNode和ResourceManager单独设置一个ip,就是指定类似注册到这个服务器中,由这个leader来管理。
1 | <!-- Reducer获取数据的方式 --> |
配置MapRed脚本:
vi mapred-env.sh,一样是配置JAVA_HOME
1 | export JAVA_HOME=/opt/module/jdk1.8.0_251 |
配置MapRed xml文件:
这里步骤多一点,复制模板,在修改文件,然后是指定MR运行在yarn上就ok了
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
1 | <!-- 指定MR运行在Yarn上 --> |
指定MR运行在Yarn上这是什么意思呢?个人理解MR计算,需要调用资源,当然是交给yarn呢!!!
总结下:
我们三台服务器,所以每个服务器运行不同的模块
- Hadoop01:NameNode、DataNode、NodeManager
- Hadoop02:DataNode、ResourceManager、NodeManager
- Hadoop03:DataNode、SecondaryNameNode、NodeManager
表格形式:
| Hadoop01 | Hadoop02 | Hadoop03 | |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | ResourceManager、NodeManager | NodeManager |
集群的启动
一般我们是一台一台启动,这样太慢,hadoop自带集群启动脚本。
配置启动服务器配置:
vi ${HADOOP_HOME}/etc/hadoop/slaves,把服务器地址填进去,注意,不能有空格,否者报错。然后分发到其他服务器
1 | hadoop01 |
启动之前需要格式化下NameNode:
1 | bin/hdfs namenode -format |
然后启动hdfs:
1 | sbin/start-dfs.sh |
启动yarn:
注意我们的ResourceManager在哪台服务器上,就在哪台服务器启动
1 | sbin/start-yarn.sh |
这样就启动起来了
1 | ip:50070访问后台 |
可以看到后台的服务都上去了
linux集群时间同步
我们linux集群执行定时任务的时候,如果时间不同步,肯定会出现问题,所以我们需要同步时间的应用【ntp】,和linux自带的定时任务【corntab】同步脚本。具体查看,在我的博客【Linux搭建项目】里。
HDFS学习
为什么需要HDFS
我们一个系统无法满足数据的存储,我们需要把数据分配到各个磁盘里去,所以我们需要一个系统来管理对台服务器上的数据,这就是分布式管理系统,HDFS就是分布式文件管理系统,不过是文件分布式管理系统的一种。
HDFS的定义
一个分布式的文件系统,就是由很多系统来实现文件管理。适合一次写入多次读出,文件已经存入无法修改,他的目录信息,和具体块的数据是分开的。
HDFS优缺点
优点:
高容错性,可插拔数据,自动同步副本数据,就算挂一个,也会很快的同步一个副本数据。可以建立在廉价的数据上去。并且是个处理GB、TB、PB大量的数据。
缺点:
无法像传统关系型数据库一样进行低延迟的数据访问,这个涉及到实时处理,后面再说。
小文件太多的话影响查询效率,因为HDFS是要存放一个文件的元数据,不管文件多大,存放的元数据大小都是差不多,如果小文件多的话,对应的元数据多,导致效率低下,小文件加起来实际并没有多少数据。
一个文件只能一个线程写,不允许多线程。
文件内容只能追加(append),不能修改。
HDFS组成架构
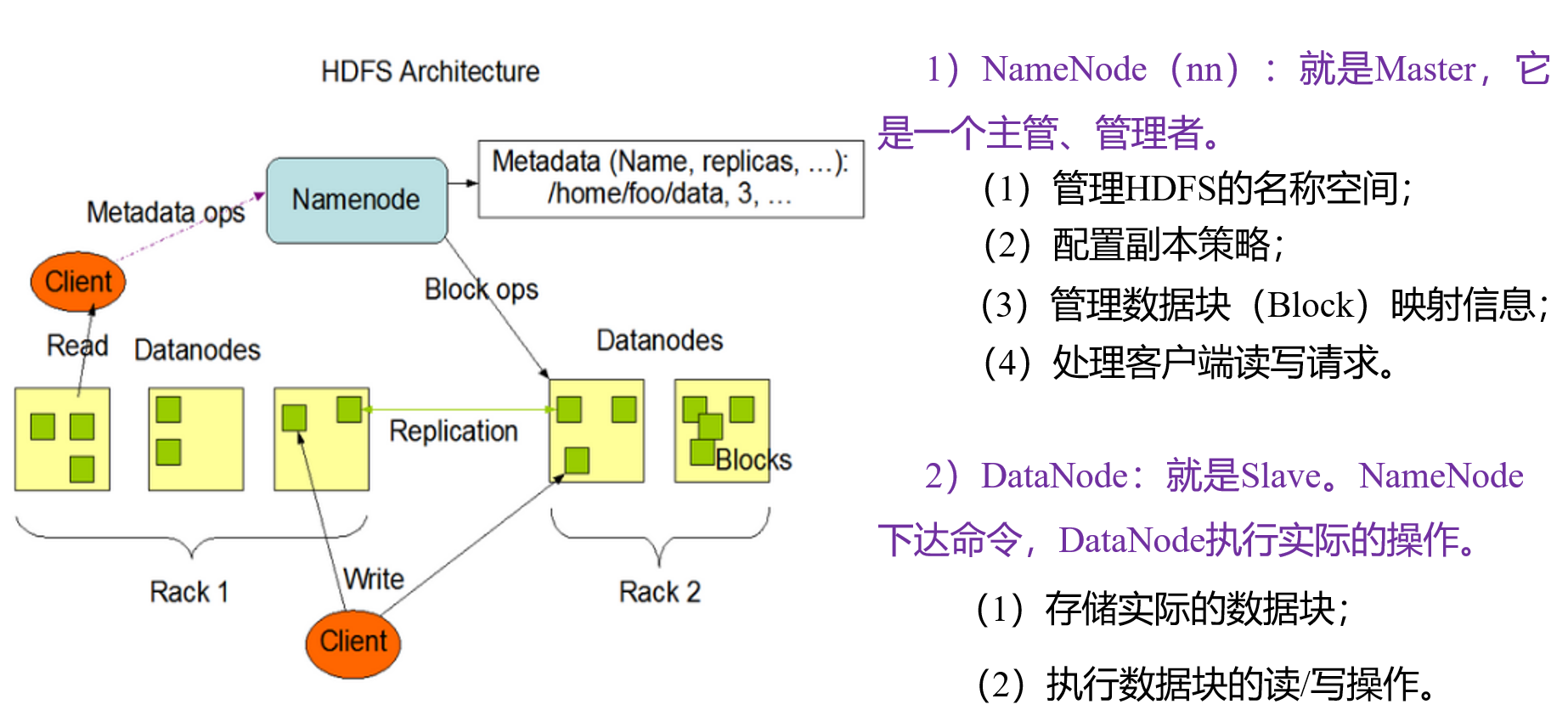
我们根据图片来理解一下。
NameNode:存放的是元数据,什么是元数据,文件的目录、大小、位置、在哪个副本…等等一些文件信息,所以他是一个管理者,他来分配我们请求过来的job。
DataNode:存放的是块数据,我们理解成实际的数据,既然分配的活都给NameNode干了,我就接收命令,读写就完事了。
HDFS块(block)概念
把文件分成一块一块的数据方便操作,但是实际上还是一块数据,不管多小的数据也会占一块的数据,而很大的数据也分为很多块数据。但是具体占的容量还是实际大小,个人理解这也是一个分布式。老的hadoop默认64M,新的默认128M。
HDFS Shell命令
前缀:hadoop fs -具体命令
举例:
创建多级目录
1 | hadoop fs -mkdir -p /temp/demo |
删除文件
1 | hadoop fs -rm -r /temp |
复制文件,从一个hdfs文件复制到另一个hdfs文件路径里
1 | hadoop fs -cp /temp /demo |
hdfs复制文件到本地
1 | hadoop fs -coryToLocal /temp /demo |
复制本地到hdfs
1 | hadoop fs -coryFromLocal /temp /demo |
上传是put、下载是get、下载多个是getmerge。我们发现除了一些特定的命令,大部分命令和linux命令没什么区别,这里我们就不多说了,以后就会慢慢熟悉了,这里不多说。下面是fs命令的帮助,看下大概都能了解了。
1 | Usage: hadoop fs [generic options] |
HDFS客户端(api操作)
配置开发环境hadoop环境
本人是win10环境,选择win的hadoop jar包,文件在我的git上,自己下,配置的环境和配置JAVA环境一样,这里就不多说了。
然后new一个maven环境,pom文件引入依赖文件即可
1 | <dependencies> |
还需要引入一个日志配置文件,名称:log4j.properties
1 | =INFO, stdout |
hdfs客户端操作API
第一步:获取配置操作对象,这个肯定是有的,我们可以设置一些专属的配置。
1 | Configuration conf = new Configuration(); |
这里就不演示了,直接看API,或者百度如何使用即可。
第二步:获取hdfs操作对象,也就是文件操作对象,我们我们需要传入三个参数
- Hadoop集群地址
- 上面的配置文件
- 操作的用户,这个很重要,hdfs也是分用户的,和linux一样
1 | FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop01:9000"), conf, "root"); |
第三步:操作文件对象API,进行文件操作。举例创建文件夹
1 | fileSystem.mkdirs(new Path("/demo/hdfs/test")); |
第四步,关闭文件对象IO
1 | fileSystem.close(); |
我们可以发现通过文件对象API大致能知道这些API的作用,下面是图片。
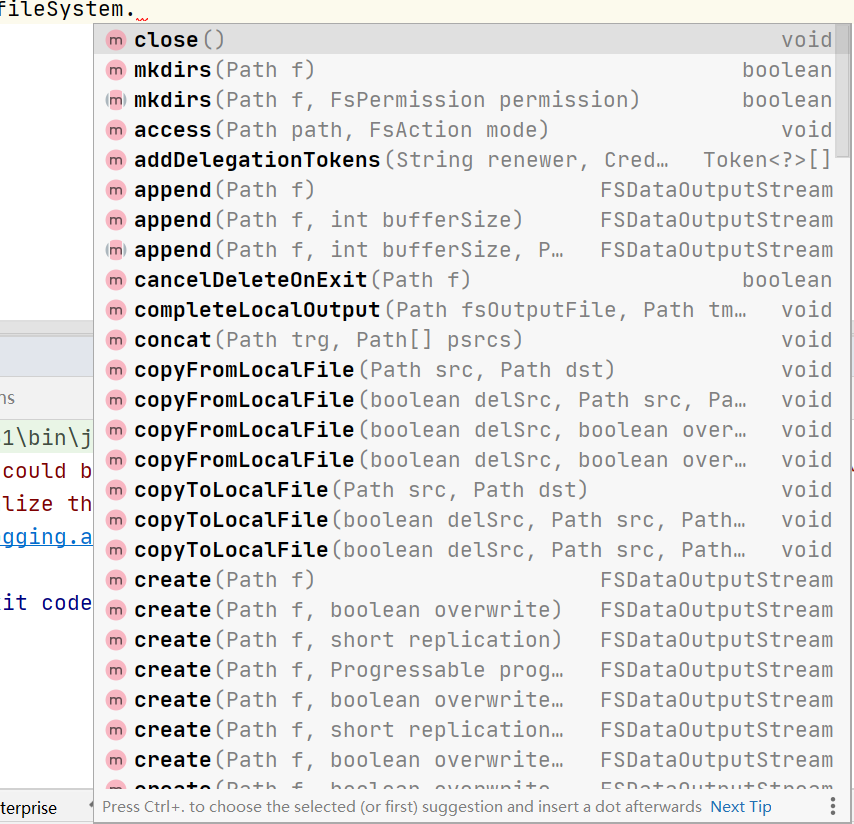
简单说几个api:
copyFromLocalFile:本地上传文件,注意第一个参数是要上传的文件的路径,第二个是要上传到哪里的文件路径。
copyToLocalFile:下载文件到本地,注意第一个参数是要下载的文件的路径,第二个是要下载到哪里的文件路径。
open:参数是路径,返回的是HDFS输入流对象。
create:参数是路径,返回的是HDFS输出流对象。
其他的api看下名称即可,就不多说了。这一块虽然是重点,但是没必要都把api都过一遍,需要的时候在练习即可。
不过,值得注意的是,永远要记得一个概念,我想从hdfs下载文件到本地,那么输入流肯定是hdfs,输出流肯定是本地。反之上传的话,那么输入流肯定是本地,输出流是hdfs。这样我们自己定义一下hfds操作的api,使用open和create这两个api来进行上传下载操作。
具体的例子:
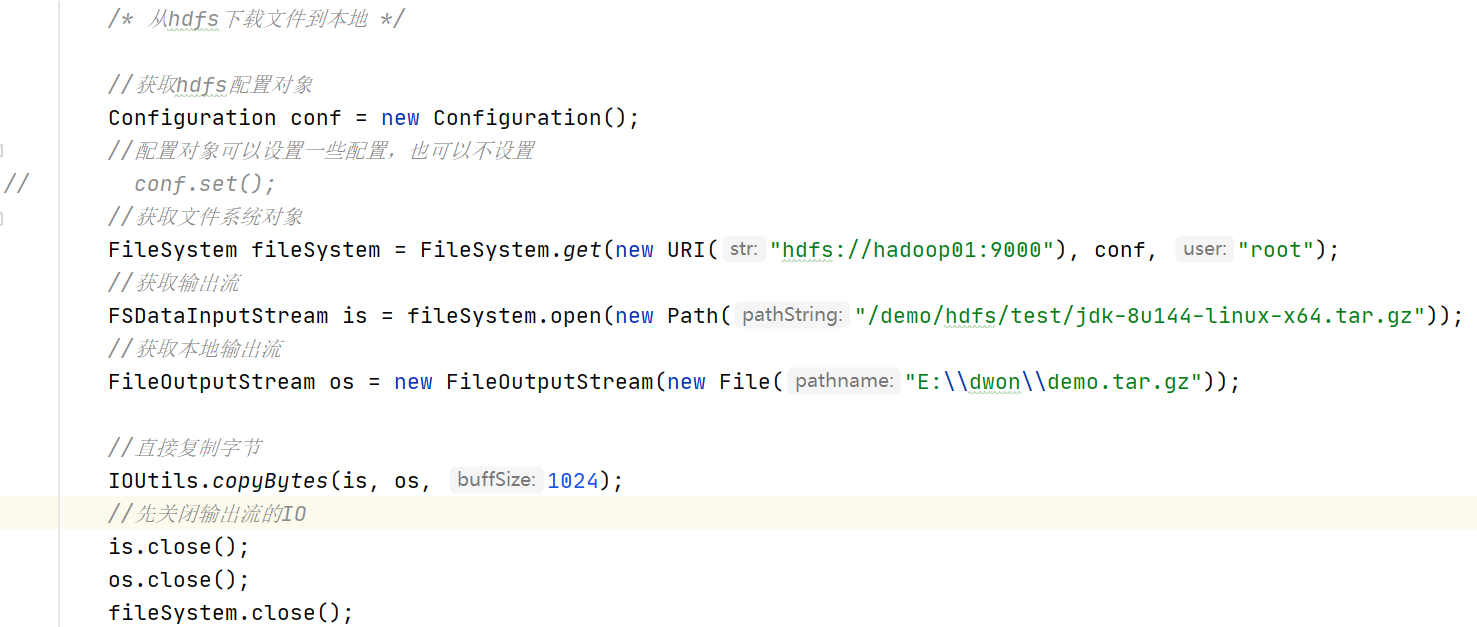
HDFS上传原理:
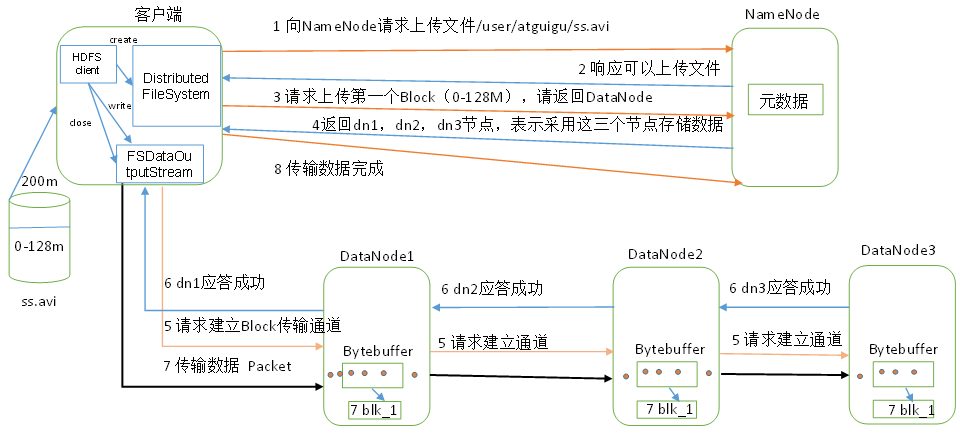
第一步:上传文件请求到HDFS客户端,客户端调用分布式文件系统(DistributedFileSystem),有分布式文件系统请求Name Node上传文件,正如我们说的Name Node是一个master。
第二步:Name Node响应给DistributedFileSystem,可以上传文件。
第三步:既然允许我上传,那我就请求上传第一个block,我们说过,hdfs的文件是分block(块)的,个人感觉这种架构存储,是为了分布式多处理。一个job可以处理多个block,而我们是分布式的,我处理A1服务器的block01,另一个线程处理A2服务的block02,那就很舒服的。
第四步:你请求了我上传到哪个Data Node,那我就给你,然后看看配置文件,一看你是三个副本啊(这里简单举个例子,可能有其他操作),那我给你三个Data Node节点那就ok了,如果没有3个,那就能给多少就给多少。
第五步:我接收到了给的Data Node信息,那我能干什么?当然是传数据了,我上传数据相当于什么?相当于本地往hdfs写数据啊,所以,需要FSDataOutputStream(FS输出流)对象,我写数据就完事了。我拿到FSDataOutputStream不可能直接咔咔往的Data Node里写,那我请求下看能不能写啊,于是请求建立通道。
第六步:Data Node收到请求后,表示没有问题,那就应答FSDataOutputStream ok,直接来吧!
第七步:我FSDataOutputStream,收到成功信号后,那就直接传就完事了。客户端开始往第一个Data Node传第一个block(会先从本地磁盘读取数据放到本地内存缓存里),一个packet为单位,第一个Data Node传完后,第一个Data Node传第二个,第二个接收完,由第二个传第三个。第一个Data Node,每传好一个packet就会放到应答队列里等待应答。
第八步:我全部传完,要给大哥说下,于是给Name Node说我好了!!!开始请求上传第二个Block直到完成。
