
Zookeeper
Zookeeper介绍
以下概念大部分来自官网
他是啥
官方介绍:ZooKeeper 是一个集中式服务,用于维护配置信息、命名、提供分布式同步和提供组服务。分布式应用程序以某种形式使用所有这些类型的服务。每次实现它们时,都需要进行大量工作来修复不可避免的错误和竞争条件。由于实现这些服务的难度,应用程序最初通常会吝啬它们,这使得它们在发生变化时变得脆弱且难以管理。即使正确完成,在部署应用程序时,这些服务的不同实现也会导致管理复杂性。
翻译的有点不准,一句话就是:分布式协调程序。好,分布式协调怎么协调?配置!维护一份配置文件,所有的分布式程序去读取这个配置文件,去做处理。
他提供了什么
官网:ZooKeeper 是分布式应用程序的分布式开源协调服务。它公开了一组简单的原语,分布式应用程序可以基于这些原语来实现更高级别的同步、配置维护以及组和命名服务。它被设计为易于编程,并使用以熟悉的文件系统目录树结构为样式的数据模型。它在 Java 中运行,并具有 Java 和 C 的绑定。
众所周知,协调服务很难做好。它们特别容易出现诸如竞争条件和死锁之类的错误。ZooKeeper 背后的动机是减轻分布式应用程序从头开始实现协调服务的责任。
他凭什么
保证:
- 顺序一致性 - 来自客户端的更新将按发送顺序应用
- 原子性 - 更新要么成功要么失败。没有部分结果。
- 单一系统映像 - 无论连接到哪个服务器,客户端都将看到相同的服务视图。即,即使客户端故障转移到具有相同会话的不同服务器,客户端也永远不会看到系统的旧视图。
- 可靠性 - 应用更新后,它将从那时起一直存在,直到客户端覆盖更新。
- 及时性 - 系统的客户视图保证在特定时间范围内是最新的。(最终一致性)
他凭什么去协调分布式的?提供简单的原语:
- create : 创建的节点数据
- delete : 删除节点
- exists : 判断节点是否存在
- get data : 获得节点数据
- set data : 修改节点数据
- get children : 获得节点数据列表
- sync : 同步自己节点数据和主数据一致
增删改查、同步全部都有了,我们只需要调用这些提供的api就可以进行对分布式配置的处理。
他的架构:

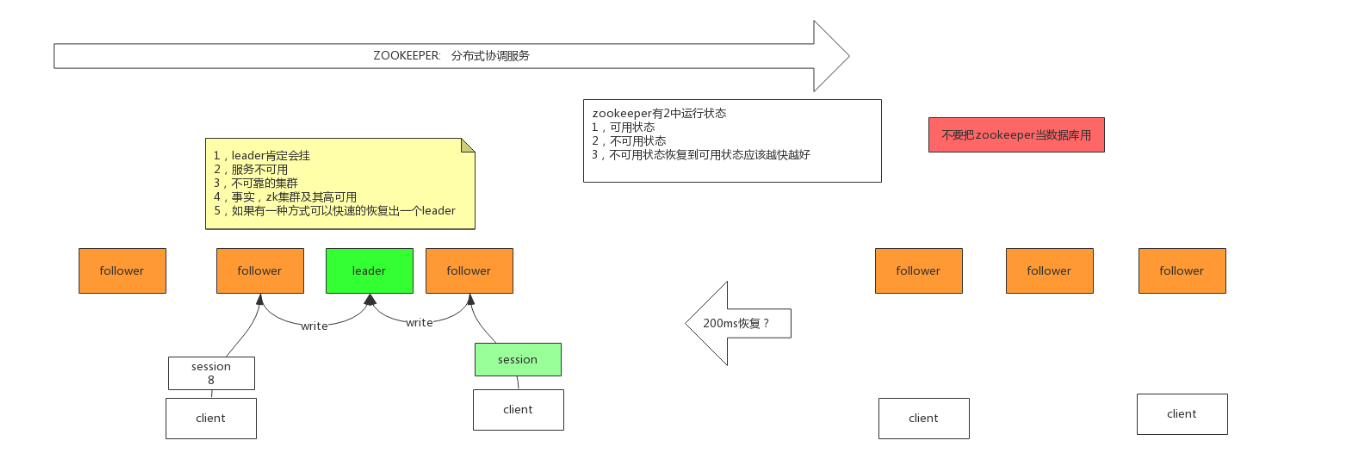
思考:他怎么保证自己数据的可靠性、高可用,分布式!!!其实这里就奇怪了嘿嘿,我们希望去处理、协调分布式系统的获取数据一致的问题,从而去引入另一个分布式系统,保证数据的可靠性,但是分布式数据系统永远永远要关注一下问题:
- 主挂了怎么办,注意zookeeper是主从模式,主只要挂了,zookeeper整个集群是不可用的,不提供服务。而zookeeper反而是高可用的,他会立马的选举新的主,如何做到的呢?我们可以看到官方介绍,zookeeper选举新的leader不到200毫秒,他是怎么做的这么快的,下面介绍。
- 数据同步,如何保证整个集群数据的同步?很简单。zookeeper提供
sync同步api,只需要获取数据的时候调用下就行。具体细节不止这些,涉及到修改数据,创建数据,数据同步,这三个数据的操作,总要会提到强一致性、最终一致性,下面介绍。 - 从挂了怎么办,客户端连接一个服务,但是,啪!这个服务挂了,zookeeper是否可以接着这个连接继续下面的工作?可以,zookeeper连接会有一个session,并且session是同步的。只需要另一个server拿到这session继续操作即可。
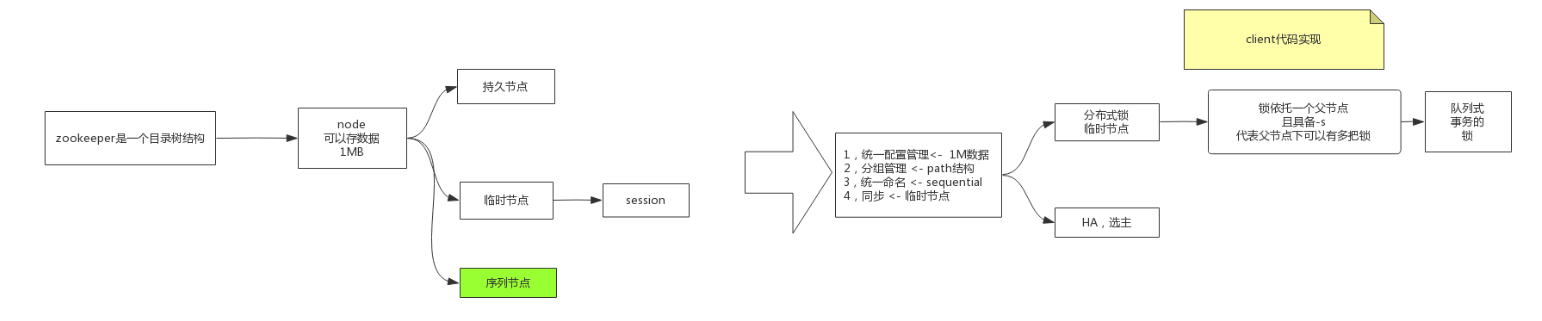
他的数据结构
官方:是分层的命令空间,就像一个文件目录,更加好的分类数据,这里没什么说的
安装使用、介绍
需要环境jdk,这里使用1.8的
下载:
1 | https://zookeeper.apache.org/releases.html#releasenotes |
这里说最新的稳定版本是3.6.3,直接下载,上传服务器,解压、设置zookeeper环境变量,一套流程我就不多bb了。

配置介绍
目录很清晰,我们直接看配置,先把配置cp一份
1 | cp zoo_sample.cfg zoo.cfg |
leader和服务的心跳时间,默认毫秒,每两秒发送一个心跳
1 | # The number of milliseconds of each tick |
初始化次数,也就是说从追随主的时候,允许等待2秒x10次,20秒的延迟
1 | # synchronization phase can take |
忍耐心跳次数,也就是说,你5x2秒等于10秒,10秒没有成功的心跳,就代表你挂了
1 | # sending a request and getting an acknowledgement |
zk的数据目录,这里我们直接自己新建
1 | # example sakes. |
zk客户端连接端口号
1 | # the port at which the clients will connect |
当前节点允许最大的客户端连接数
1 | # increase this if you need to handle more clients |
配置集群服务节点,server后面跟着的.x是id,2888和3888是zk服务之间的通信和选举leader端口
- 2888
- 3888
1 | server.1=192.168.166.11:2888:3888 |
实际操作
给持久化目录放一个myid,和上面的server后面的一直
1 | echo 1 > /var/zyl/zk/myid |
分发zk到另外三个服务
1 | scp -r ./modul root@192.168.166.12:`pwd` |
分别把另外三台服务器的myid改下,创建数据目录。然后启动两种方式
- 后台启动:
zkServer.sh start - 前台启动:
zkServer.sh start-foreground
我们看日志直接前台启动node01
1 | zkServer.sh start-foreground |
会发现各种报错
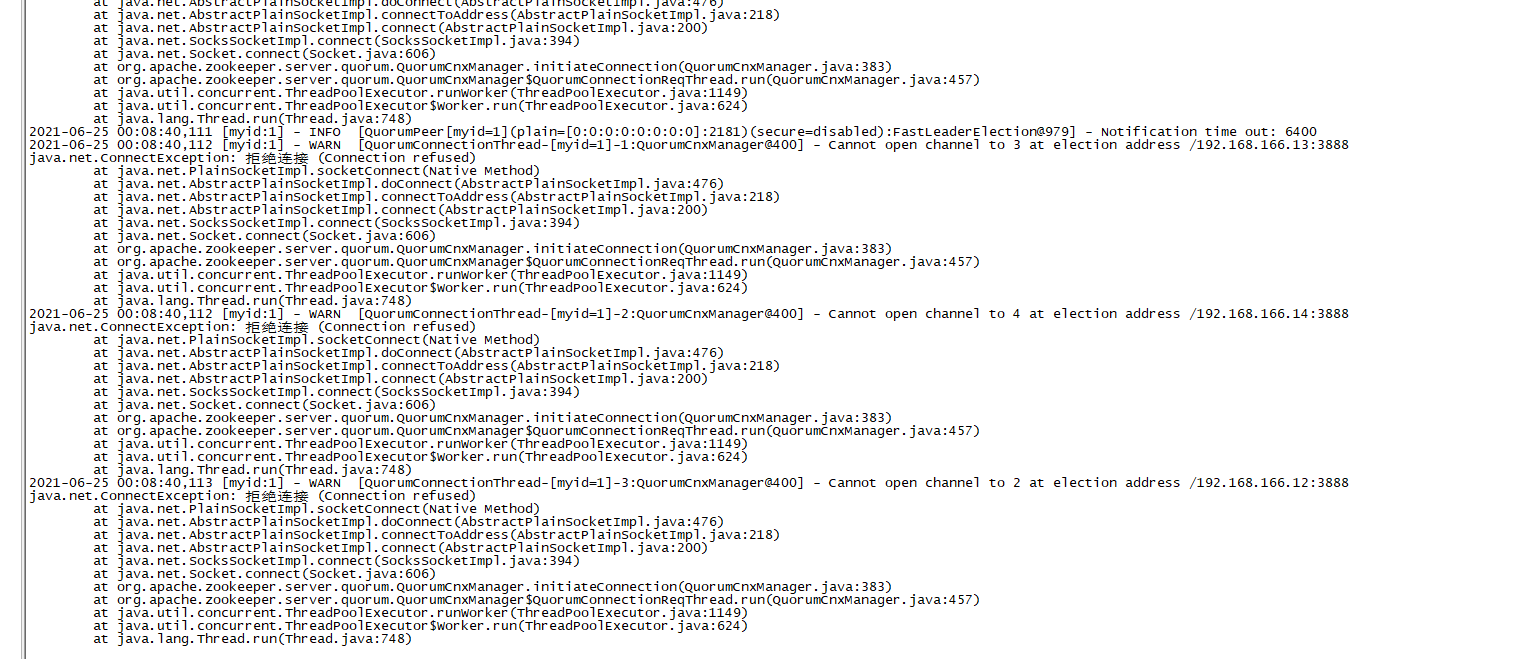
不慌继续启动node02,发现node02还是报错
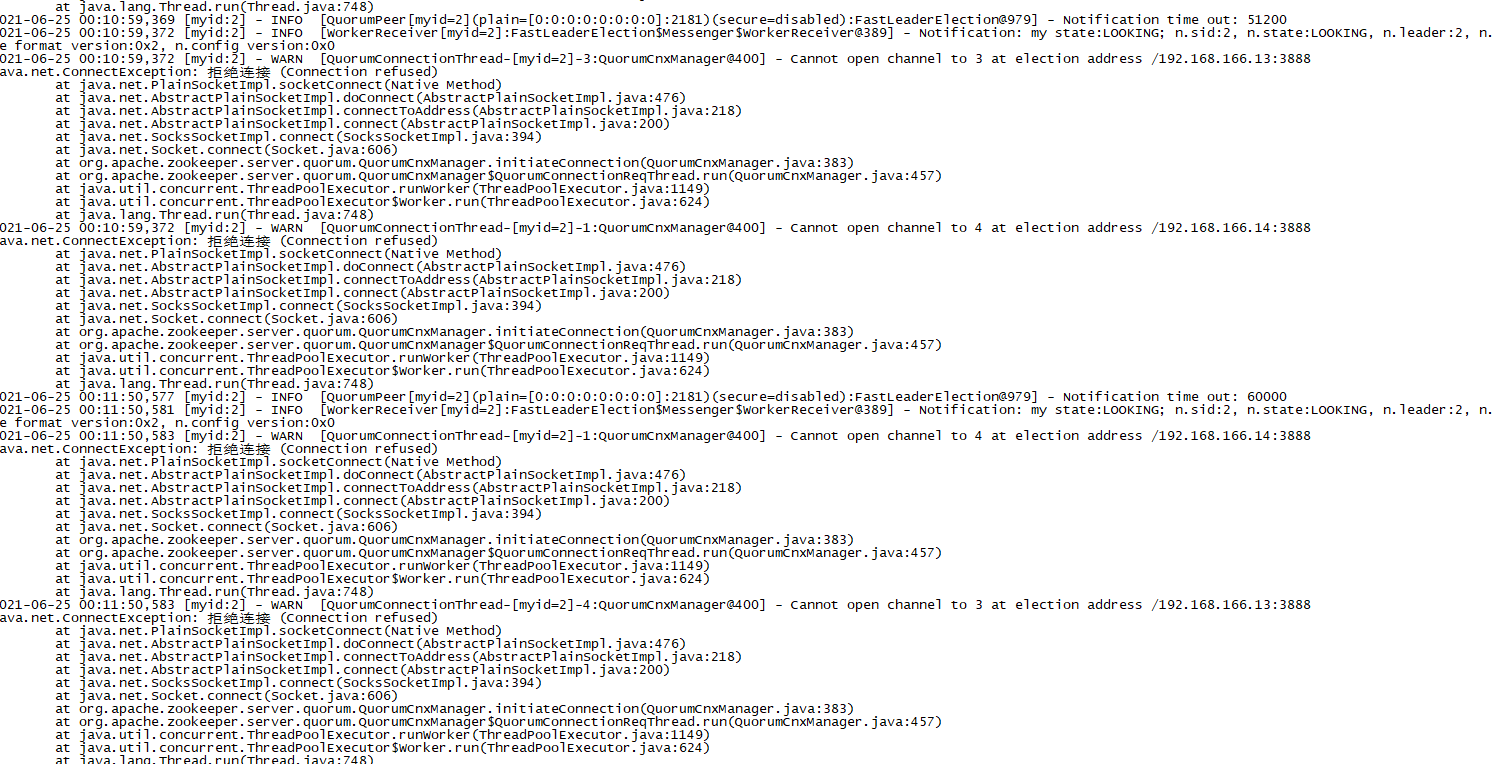
不慌继续启动node03,这个时候瞬间就不报错了,怎么回事呢?因为服务可以过半了!服务可用了,因为zk集群必须服务过半,才能运行,也就是说,zk服务存活数必须>2台,才能正常工作,为什么呢?下面会说为什么
连接客户端,看到日志,提示提交一个全局的session,id是0x1000225088c0000,查看node02,node03都有这个提示,说明session同步了。我们还可以使用他提供的原语对数据进行操作
1 | zkCli.sh |
session日志
1 | 2021-06-30 13:58:21,401 [myid:3] - INFO [SyncThread:3:FileTxnLog@284] - Creating new log file: log.100000001 |
API操作
查看目录,会发现他的根目录有个zookeeper。子目录下有
- config:zookeeper配置,存放在集群服务ip
- quota:未知
1 | [zk: localhost:2181(CONNECTED) 12] ls / |
创建一个节点
1 | [zk: localhost:2181(CONNECTED) 16] create /n1 "" |
创建n1子节点
1 | [zk: localhost:2181(CONNECTED) 18] create /n1/B1 "hello world" |
查询数据
1 | [zk: localhost:2181(CONNECTED) 20] get /n1/B1 |
修改数据
1 | [zk: localhost:2181(CONNECTED) 21] set /n1/B1 "hello" |
删除数据
1 | [zk: localhost:2181(CONNECTED) 29] delete /n1/B1 |
查看节点信息,详细介绍:
zk是有事务这个概念的,每个事务都有事务id的概念,而事务id肯定是递增的,是zk的leader来维护的。
cZxid:创建的事务id
mZxid:这个节点的修改的事务id
pZxid:当前这个节点下,创建最后的事务id
ephemeralOwner:这个节点临时持有者,当临时持有者连接断开,session回收,这个节点就自动消亡,就是伴随着session的会话期。
1 | [zk: localhost:2181(CONNECTED) 1] stat /n1 |
那就测试上面的临时的节点测试,开启两个node01,node02客户端。node01设置临时节点
1 | [zk: localhost:2181(CONNECTED) 1] create -e /n2 "" |
node02查看
1 | [zk: localhost:2181(CONNECTED) 0] ls / |
关闭node01客户端连接,node02查看,你会发现临时节点n2不是马上过期的,是等session过期后,才消失不见的。
1 | [zk: localhost:2181(CONNECTED) 3] ls / |
创建序列节点,就是创建节点后面带着序列,可做分布式锁的操作
1 | [zk: localhost:2181(CONNECTED) 16] create -s /n3/a |
api的操作就说到这里,详细的操作,和对接spring的时候详细解释,我们直接退出客户端,发现30秒后有日志,说是session 30秒连接超时,关闭这个session,永远的记住,zk的连接是有session的,并且session是同步的。
1 | 2021-06-30 14:21:17,810 [myid:3] - INFO [SessionTracker:ZooKeeperServer@610] - Expiring session 0x300000569480000, timeout of 30000ms exceeded |
事务id的概念
这个东西需要单独拿来说下,直接说概念,事务id是单独由zk的leader管理,不管是对数据的增加、修改,或者是session的同步、删除,都会消耗事务id。
事务id格式:0x100000002,是64位,一个数字代表4位,低32位是事务id递增的范围,第一个数字是zk的leader的版本号,怎么理解这个版本号,是代表你是第几个leader,1前面的0是省略的。
增加、修改数据很好理解,那么如何理解session同步,事务id要+1呢,这里我们做个试验。
node01开启客户端,设置一个值查看事务id,发现事务id是0x100000010
1 | [zk: localhost:2181(CONNECTED) 1] create /n2 "" |
node02连接客户端,node01在创建一个节点,并查看数据版本。发现事务id由0x100000010变成0x100000012,那0x100000011呢?
1 | [zk: localhost:2181(CONNECTED) 3] create /n3 "" |
不慌,node02退出客户端,node01创建数据,并查看数据,发现怎么是0x100000014
1 | [zk: localhost:2181(CONNECTED) 6] stat /n4 |
是不是zk创建数据,就是两个要加两个事务id啊,node01继续创建数据并查看数据。
1 | [zk: localhost:2181(CONNECTED) 7] create /n5 "" |
发现他是0x100000015,这里已经说明了,session的同步是要经过事务的,session消亡了,自然也要同步,会进行事务操作。
连接介绍
明确一点,zk的服务是互相通信的,他通过2888、3888端口去互相通信,那么怎么看呢?命令 netstat -natp | egrep '(2888|3888)',直接开搞,查看node04节点,连接情况。
说明下:
第一条:自己的端口3888
第二条:自己端口47090,连接到192.168.188.182的2888端口
第三条:自己端口39574,连接到192.168.188.181的3888端口
第四条、第五条同上,就不多解释了。
总结:自己开了3888端口,然后连接node03的2888端口,分别连接node01、node02,node03的3888端口。
1 | [root@node04 ~]# netstat -natp | egrep '(2888|3888)' |
这个时候发现了什么?2888连接了一条,其他3888连接了3条,这个时候不妨大胆的猜测,2888端口是leader的通信端口口,node03是leader,node01、02、04需要分别要连接到node03的2888端口,而为何还要连接3888端口呢?选举用啊,你不通信如何选举啊。
查看node03连接情况。直接总结:
- 自己开了2888、3888端口
- 自己的2888端口,分别被node01、node02、node04连接
- 自己开端口连接node01,node02
- 自己的3888端口被node04连接
很奇怪,为啥自己开端口不连接node04啊
1 | [root@node03 ~]# netstat -natp | egrep '(2888|3888)' |
分别查看node01、node02连接情况
node02:
1 | [root@node02 ~]# netstat -natp | egrep '(2888|3888)' |
node01:
1 | tcp6 0 0 192.168.188.180:3888 :::* LISTEN 1386/java |
这个时候需要画图去看他们连接情况,画图的思路,首先,node01、02、04都会连接到node03的2888端口,这个不用画,我们只看自己开端口连接3888端口情况。
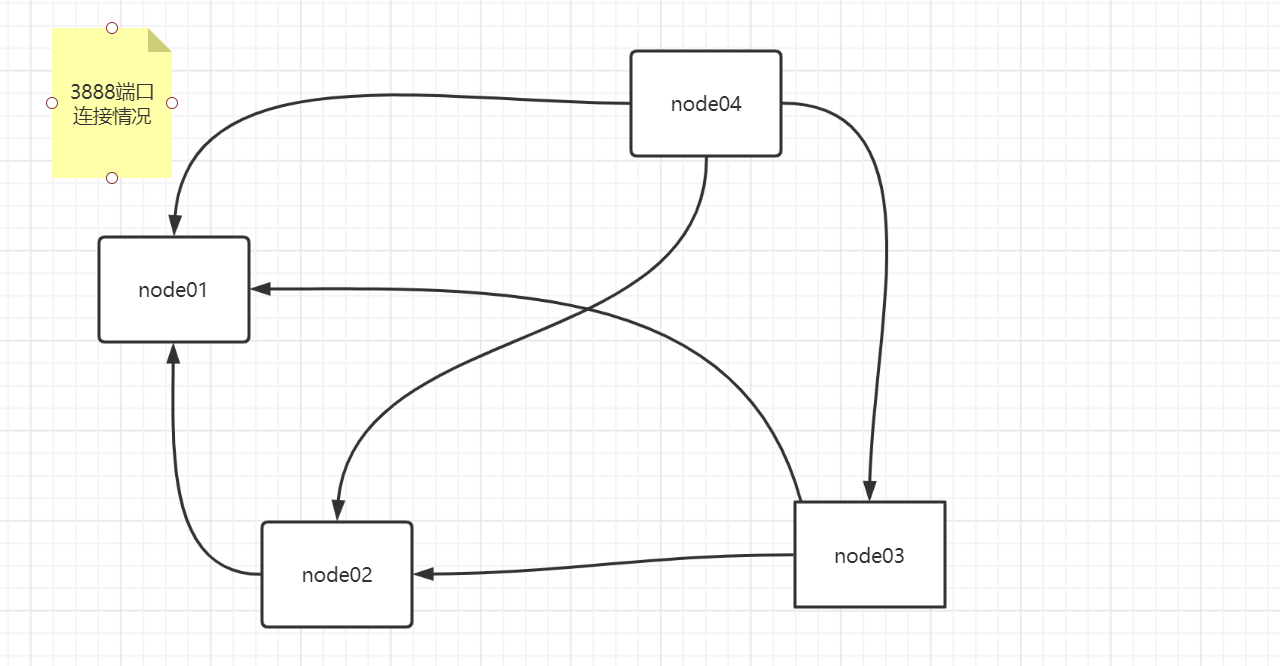
zk采用的是极少的连接进行通信,保证了不会浪费连接,和任意节点挂了都不会影响其他节点的通信。举例子:
node04和其他三台都连接上了,假如他挂了呢?连接持有拓扑
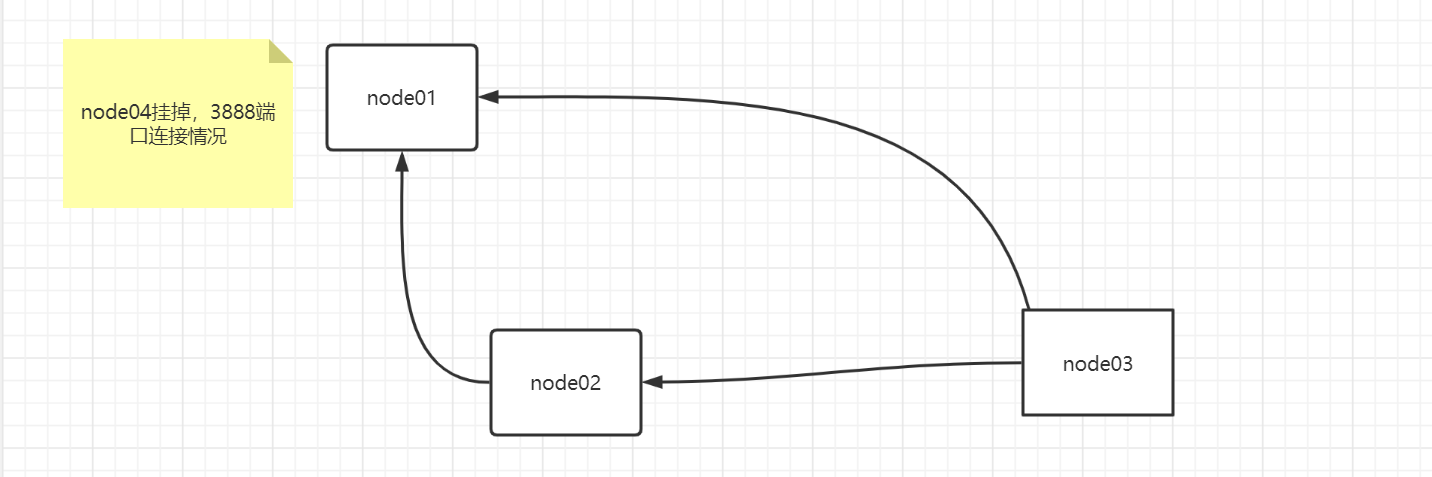
你会发现还是不影响,总会有节点持有全部的连接,很好理解这个概念,而我们似乎发现一个规律:
4个节点的3888连接情况是,3、2、1,逐渐减少,并且好像是和设置的zkid有关,是不是很有意思。
使用介绍
已经把他的具体的操作、概念都BB了一遍,其实,你总结就是,分布式系统想通过一份配置文件去管理,客户端实现,需要维护、管理操作,zk已经帮你做了,并且,这份配置文件还是高可用的,如果节点挂了,几百毫秒马上恢复。
当然不仅如此,比如,想要实现分布式锁,也是可以很轻松的实现的,下面在介绍吧。
核心概念介绍
一项技术的发展,必然由不同的概念去支撑他,zk就是这样,他的灵魂就是来自ZAB算法!!!而ZAB算法衍生于Paxos算法。
另外需要提及的一点是,分布式只要是涉及数据的系统,无法避免的是
- 数据同步问题,数据同步分为强一致性、弱一致性、最终一致性,
- 分布特有的CAP问题
而paxos就是解决的是数据同步问题的,所以zk是典型的CP模型。
