
多线程与高并发
基础的概念
什么是线程
一条程序里,不同的执行路径,就是线程
什么是进程
一条程序的最小执行单元
启动线程的三种方式
- new Thread
- 继承runnable
- 线程池
线程的基础方法
睡眠
当前线程睡眠x毫秒
1 | Thread.sleep(5000) |
让出cpu
当前线程让出cpu执行,返回就绪状态
1 | Thread.yield() |
等待其他线程执行
就是线程2方法,等待线程1方法执行完在执行
1 | t1.join() |
线程状态
大致分为五个状态
- New:一个线程对象刚刚创建的状态
- Runnale:就绪状态,一个线程创建后,其他线程调用start()方法,变为就绪状态。该线程位于可运行线程池,只需等待获取CPU的使用权。
- Running:运行状态,就绪状态线程获得CPU使用权,开始执行代码。
- Blocked:阻塞状态,因为某些原因,让出cpu使用权。直到变为就绪状态,才有机会成运行状态。阻塞状态又分为三种
- 同步阻塞:运行线程获取同步锁的时候,若该锁被其他线程持有,则JVM会把该线程放入锁池中
- 等待阻塞:Waiting,让出cpu使用权,线程变为等待状态,该状态无法主动唤醒,只能等待其他线程调用notify或notifyAll唤醒。
- 其他阻塞 :运行线程调用sleep()或join方法,该线程变为阻塞状态,直至sleep超时或join执行完毕,该线程变为就绪状态
- 死亡状态:现在run()方法执行完毕或异常退出,线程结束生命周期。
锁
锁是干啥的呢?当对一个共享的状态变量进行修改操作的时候,我们期望b线程操作是a线程操作后的数据,不能是a线程在操作而b线程同时在操作,于是加锁。java的锁需要一个锁对象,jvm会把一个对象身为锁的状态放在两位字节码上,具体是什么,后面继续聊。
而常用的是synchronized,synchronized的加锁方式有三种方式
- 直接在一个代码块使用synchronized声明,并申明锁是哪个对象
- 直接在方法加synchronized关键字,但是分为静态方法和非静态方法
- 静态方法:锁是对象的class文件,就是T.class
- 非静态方法:锁是this,就是这个对象
其他的锁的知识,后面再聊
可重入
一个线程方法m1加了synchronized关键字被调用,在方法体里面同时调用m2方法,m2方法同时被synchronized加锁,那么是否能调用成功,答案是可以的,因为他们是一个线程持有同一把锁,所以synchronized必须可重入。个人感觉加锁的目的是为了线程的安全,既然是同一线程持有同一把锁,说明他是可以顺序执行的,而非并发执行的线程。涉及到其他线程的调用,则必须被锁住。
synchronized的底层实现(锁升级)
jdk1.5之前,都是重量级锁(OS),以后就优化成了锁升级,就是偏向锁–>自旋锁–>重量级锁
- 偏向锁:一个线程启动第一次获取了锁,锁对象并未被加锁过,锁对象会在对象头(makeword)记录这个线程的id,当这个线程调用的另外的方法获取的锁还是这个锁的时候,是可以直接执行的。这个时候这个锁对象是并未加锁的。
- 自旋锁:当一个线程访问一个方法,这个方法上的锁被另一个线程所持有,这个线程会类似的while(true)循环不断尝试获取这把锁,尝试次数十次,如果并未获取到这把锁,自动释放cpu使用权,变为等待状态,升级为重量级锁。
- 重量级锁:在锁池等待执行,这个是OS级别的。这个怎么理解OS级别呢?当一个线程判断锁是重量级锁的时候,会自动释放cpu执行权,进行阻塞,但是每次阻塞或唤醒都需要OS来帮忙,并且在这个过程中,还会由用户态向内核态的转换,转换也是非常耗费时间的。
注意,锁的升级是不可逆的,那么什么时候使用自旋锁和重量级锁呢?一个方法执行特别快并线程数量不多的时候,使用自旋锁,其他情况使用重量级锁,因为自旋锁会占用cpu使用权!
volatile && CAS说明
volatile关键字
volatile是一个关键字,作用在属性上,有两个作用,其他线程可见、禁止重排序。但是注意的是volatile并不能解决高并发问题!!!为什么,看下面的介绍。
线程可见
这个和jvm内存有关系,我们都知道jvm是有堆内存的,一个对象的是放在堆内存里,而线程也是有自己的区域,当一个线程需要使用堆内存的对象,是直接复制一份到自己的工作内存,我们直接简称线程工作内存。
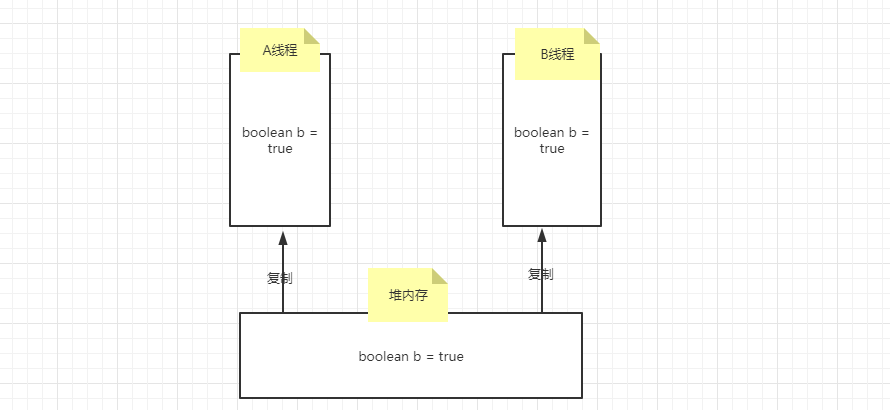
那么会有这样一个场景,两个线程,同时对一个对象进行使用,那么在他们自己的工作内存里都会复制一份数据。假如A线程修改了数据,B线程并不是直接获取到的,可能会有一定的时间去同步,那么在这个时间当中,可能会引起一些业务的错误,而volatile关键字就是给对象变为线程可见,当修改了,其他线程立刻就能看见。
禁止重排序
什么是重排序呢,就是说我们对CPU发出指令A、B、C、D操作,他执行的时候可能是B、A、D、C操作,具体原因我们不去深究,知道他是为了CPU的优化就行。那么会导致什么问题呢?
我们继续举例子,Object o = new Object对于CPU分几步呢?三步!分配内存、初始化、赋值。进行这个三步,可能会是分配内存、赋值、初始化,最终的逻辑不会出问题,反正他对象new出来了啊。但是,如果,在他赋值完毕的时候,获取到了这个对象并使用,这个时候并未初始化,这个时候就会出现问题。这个问题,会在单例模式的中第一个创建对象的时候出现。单例模式搭建都很熟悉,这里就不多说了。
CAS
CAS又叫自旋锁,但是他不是加锁,所有概念的提出就是为了解决问题,这个解决的问题,是为了解决并发的数据问题。我们继续举例。。。
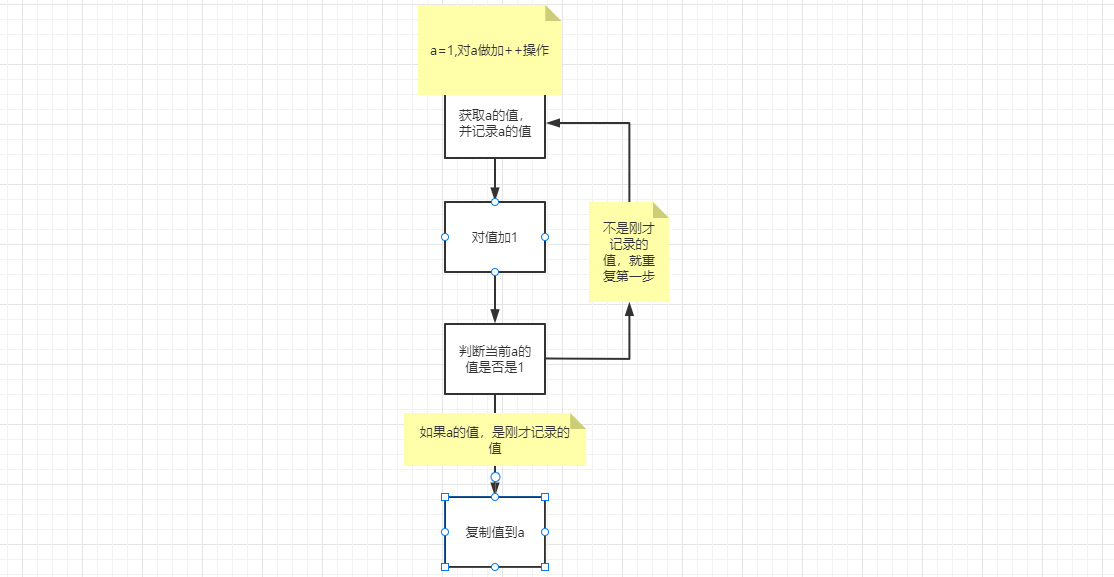
对一个count+1需要三步,获取count值、对count+1、赋值到count,在高并发的场景下,会在获取count值出现并发问题,就是多个线程同时获取到count为通一个值,那么这些线程做的操作,也只是让count+1,正常应该是+线程数量。那么CAS是怎么操作呢?如下步骤:
- 获取count值,并记录
- count值加1
- 赋值之前,判断值是否等于刚才记录的值
- 如果不等于,返回第一步继续操作
- 如果是赋值到count
当然,这个还会有一个问题,就是会出现ABA问题,就是A线程对count做加1操作,但是B线程对count做加1操作,然后又做减1操作,当前count还是那个数据,但是他的性质已经变了,他是已经被修改的值,只不过他又返回到原来的数据。这个解决的方法很简单,只需要在记录值的时候,加一个版本号即可,但对于基础类型来说,你改变值又变回之前的值,对我来说并无所谓,但是对引用类型的数据就可能会有变化,因为引用类型里面的值可能发生变化。
JUC包下AtomicXXX类与新的同步机制
AtomicXXX
AtomicXXX类无锁自增类,什么意思呢?就是多线程对一个值做自增操作,因为并发问题,就要给自增方法啊加锁,而加锁会有性能问题。而AtomicXXX可以直接调用api做自增操作,不需要加锁,而他的核心逻辑就是上面提到的CAS,emmmm。。。。api我就不说了,记住逻辑是cas操作就行。
LongAdder
和AtomicXXX一样的功能,自增无锁CAS,不过他是分段式锁,什么意思呢?他有一个数值,请求api来了,我数组0号位置做++操作,另一个请求来了,或者某个条件触发了,我数组1号位置做++,这两个位置就是两把锁,最后取结果的时候,我给这两个位置的数值相加就行。当然这只是举例,逻辑差不多这样的。而这个锁也是CAS操作,可以理解成Atomic式的分布式操作
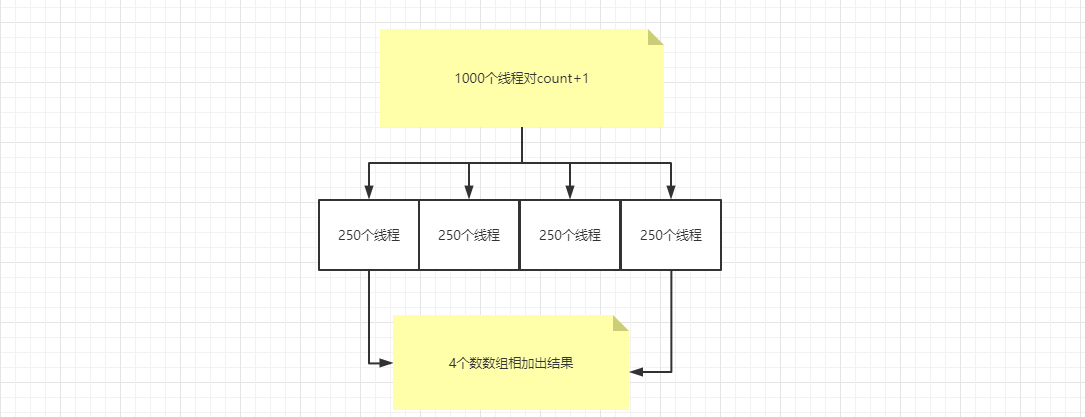
测试add各个add方法性能
这个时候,就会有疑问,哎呀,这两种封装类的和我实际加syncronized哪个性能好、时间快呢?不多bb做个试验,代码就不放出来了,太长了。
100个线程:

1000个线程:

经过测试发现,在线程少的情况下synchronized的性能不及其他两个类,而线程数多的时候反而是synchronized快。而LongAdder无论时间少还是多,是比AtomicLong时间快了,这个应该能猜到,因为LongAdder用的是分布式CAS锁。
以上测试不同环境可能有不同的结果,仅供参考。
ReentrantLock
synchronized锁我们已经很熟悉了,可以加在代码块、方法声明上,而还有另一种锁,就是api式的锁,其实核心是cas锁,可以理解成自旋锁。使用的方法很简单,直接声明即可
使用介绍
创建
1 | ReentrantLock lock = new ReentrantLock(); |
加锁
1 | lock.lock(); |
解锁
api很简单,需要注意的是unlock()必须放在finally里,必须要手动解锁。
1 | lock.unlock(); |
尝试加锁
尝试加锁,如果有别的线程执行这把锁返回false,如果加锁成功返回true,但是无论获不获得锁代码都向下执行,不过可以对返回的状态进行不同的业务逻辑操作
1 | b = lock.tryLock(); |
尝试加锁并等待X时间
在x时间内,尝试不断的尝试加锁,如果在x时间内加锁成功,则返回true,否则返回false
1 | b = lock.tryLock(9,TimeUnit.SECONDS); |
ReentrantReadWriteLock(读写锁)
有这样一个场景,对某个数据,读的请求很多,写的请求很少。那你肯定会思考,那我这边给写的方法加锁,读的方法加锁不就好了,但是这会产生一个问题,就是我写的时候,代表我不希望你读数据呢,因为对于我来说,当我决定写的那一刻,代表这个数据一样是旧的数据,所以,你不能在读了。
于是,我期望,读的时候可以像没锁一样,但是我写的时候,你不能读,等我写完,你在读!而读写锁就是干这个事情的。
使用介绍
创建
1 | ReentrantReadWriteLock r = new ReentrantReadWriteLock(); |
创建读锁
1 | ReentrantReadWriteLock.ReadLock readLock = r.readLock(); |
创建写锁
1 | ReentrantReadWriteLock.WriteLock writeLock = r.writeLock(); |
解锁
读写锁都是unlock(),读锁也是要加的,不然怎么能在读的时候不让读呢
1 | readLock.unlock() |
验证
上面说的只是我们的理论,那么我们如何验证呢,这边通过代码验证
读逻辑
注意,需要模拟,前置业务处理的时间,不然代码执行太快,达不到我们想要的效果。这里读是加锁的方式是trylock(),因为我们需要验证锁是否别写锁持有。
1 | void read() { |
写逻辑
这里的写逻辑要加上模拟处理时间
1 | void write() { |
结果
读锁遇到前置业务处理,被写逻辑抢到锁

写锁处理完逻辑,读逻辑马上抢到了锁,并且接下来继续读。

CyclicBarrier(栅栏)
栅栏就是挡的意思,设定一个阈值,在某个点拦截线程,当拦截的线程数等于这个阈值的时候,开始执行下面的代码,需要注意的是,如果拦截的线程数一直小于阈值的时候,拦截点的下面的代码会被一直拦截。
使用介绍
创建
创建的时候声明阈值,还可以传入相应的执行逻辑,这个执行的逻辑,是达到阈值后执行的逻辑
1 | CyclicBarrier cyclicBarrier = new CyclicBarrier(20,()->{ |
拦截
其实没什么好说的,在线程里拦截即可,就会一直在那里阻塞着,知道等待线程数达到设定的阈值
1 | System.out.println("线程执行了"); |
用处说明
这个时候就会去思考,这个有什么用啊,有这么一个场景,我有个业务,需要去查询数据库、请求http、请求磁盘文件,然后给这三个结果合在一起,正常情况下单线程顺序执行即可,在最后合个结果。但是这样太慢了,于是,我想并发去做,一个线程查询数据库,一个线程请求http,一个线程请求磁盘文件,我们需要等待这三个线程的结果,于是栅栏就可以直接解决这个问题。就是解决多线程处理数据的问题。
LockSupport
使用介绍
加锁
加锁调用很简单,直接加锁就行
1 | LockSupport.park(); |
解锁
解锁,需要另一个线程调用,并传入线程对象。不过有意思的是,解锁如果在线程加锁之前调用,那么是直接解锁的。
1 | LockSupport.unpark(t1); |
用处说明
个人感觉比较方便的控制程序,我期望B线程调用完,A线程能够执行。没什么好说的
Phaser
这个类提交特殊,可以理解成多个栅栏,这个是可以由一组操作组成一个操作,设置好需要拦截的栅栏数,线程过来的时候,直接拦截加锁。直到线程数到设定的阈值,直接释放。当然不仅如此,可以监控每个栅栏的阶段
使用介绍
继承类并覆盖方法
我们可以看到监控了栅栏结束了,可以做一些操作,这里的return的结果是代表是否要继续执行拦截,还是直接结束,false是继续,true代表结束
1 | class GsPhaser extends Phaser { |
设置线程阈值
1 | gsPhaser.bulkRegister(7); |
设置栅栏
代表我这个线程在这里等待着,直到达到设置的线程阈值
1 | gsPhaser.arriveAndAwaitAdvance(); |
释放栅栏
不等待了,直接执行,如果不执行这个方法,那么栅栏会一直拦截着
1 | gsPhaser.arriveAndDeregister(); |
Semaphore
允许几个线程同时执行,很好理解,换句话说,锁只能容忍一个线程去执行方法,而semaphore可以指定x个线程同时执行这个方法。
使用介绍
创建
需要指定允许线程同时允许的数量
1 | Semaphore semaphore = new Semaphore(1); |
加锁
允许运行线程的数量-1
1 | semaphore.acquire(); |
解锁
允许运行线程的数量+1
1 | semaphore.release(); |
Exchanger
线程之间交换信息,没啥说的,就是线程1调用api,线程2调用api,互相交换信息。需要注意的是,只能两个线程互相交换,如果只有一个线程,那么只能在那里等着
使用介绍
创建
1 | Exchanger exchanger = new Exchanger(); |
发送消息
1 | Object exchange=exchanger.exchange("哈哈"); |
