
java面试
java面试
java基础面试题
java基础类型
总共有8种,分别是
byte、bool、char、short、int、long、float、double
面向过程是什么
面向过程是分析解决问题的步骤,然后用函数把这些步骤一步一步实现,然后再使用的过程中一一调用即可,性能较高
面向对象是什么
把构成问题的事务分解成各个对象,而建立对象的目的不是为了完成一个一个步骤,而是为了描述某个事物再解决某个问题中发生的行为,所以衍生出面向对象的三个特性,封装、继承、多态,所以易维护、易复用、易扩展。容易设计出低耦合的系统,但是他的性能肯定比面向对象要低。
重写和重载的区别
重写
主要是子类重写父类的方法,方法名、返回值、方法参数必须相同,访问修饰符一定要大于重写的访问修饰符
重载
相同的方法名,不是的参数是重载,返回类型可相同也可以不相同
什么是内部类
在java中,可以将一个类定义在另一个类中,分为成员内部类,匿名内部类、局部内部类、静态内部类

HashCode的作用
java集合有两类,list和set,前者可以重复,后者不可以重复,那么怎么去判断是否重复,就需要使用equals方法,但是每次都使用这个方法,效率比较低,于是我们可以把对象计算成,一个哈希码,方便分组存储
mysql面试
预读取
当server来查数据库的时候,会有个预读取,就是从mysql多读取一点数据,加载到缓存区,一次读取4k,读取4次,总共读取16k。为什么要这么做呢?
是为了加速数据的读取
buffer pool
上面说到了mysql会有预读取,那么读取到哪呢?缓存区!这个缓存区就是buffer pool,默认是128m,这个可以自行设置缓存区大小,上面的预读取大小是不能设置的,除非重新编译mysql源码。
那么当buffer pool设置的内存满了怎么办,会有一个淘汰策略:LRU,淘汰冷的数据,mysql的LRU是一个链表,有8分之5的热区,8分之3的冷区,当数据第一次记录到buffer pool那么他会把数据放在冷区的头部,当1000毫秒类这个数据被再次访问,就会把它放到热区。
redo log
什么是redo log,这个是记录buffer pool得日志,因为buffer pool是一个内存数据,当电脑断电之后内存数据会丢失,所以会有个redo log日志来记录buffer pool的数据。
undo log
撤销日志!记录事务操作前的状态,当事务操作失败之后,会从这个日志回滚数据。
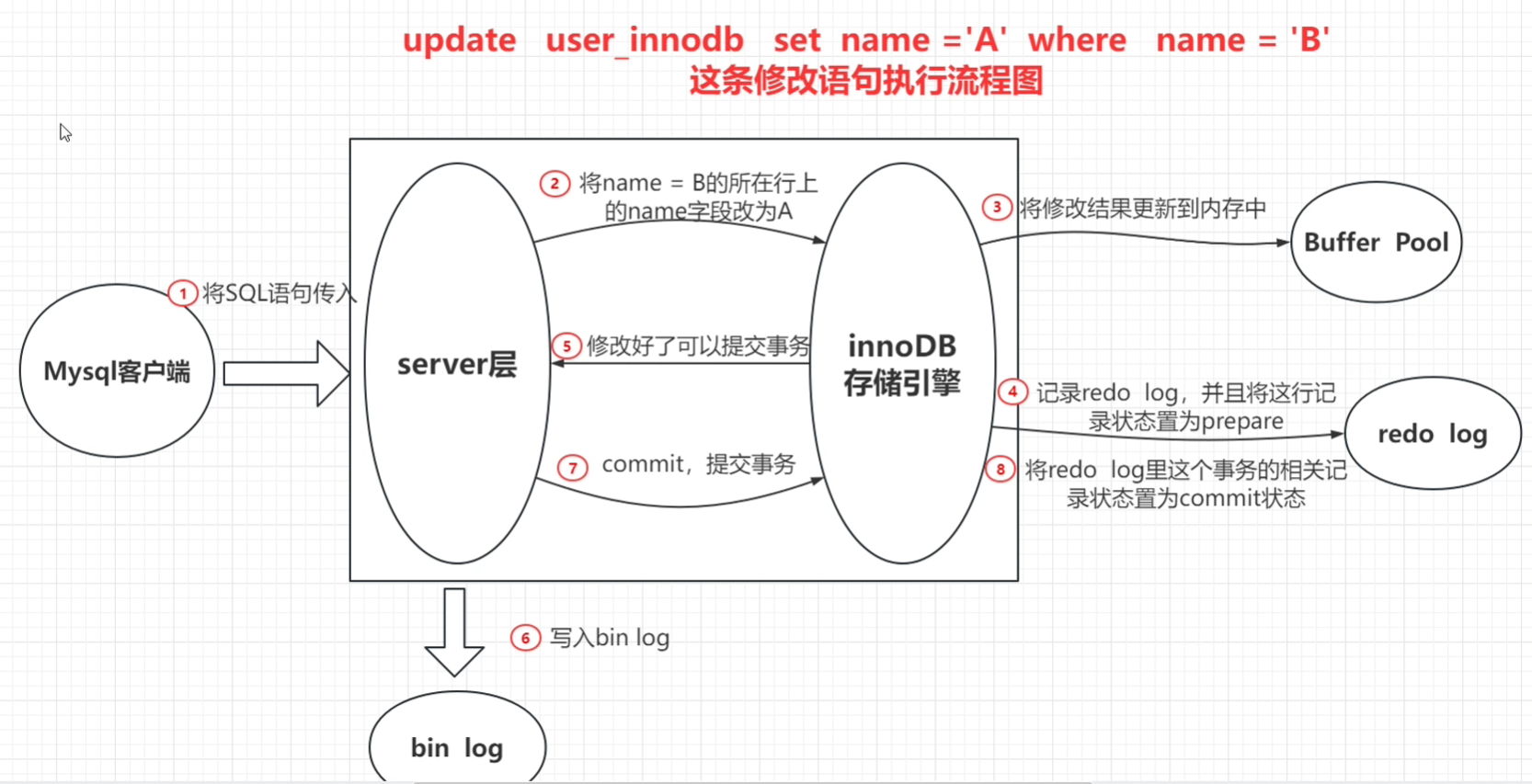
更新操作流程
- 从存储引擎,拿到数据,记录到buffer pool,返回给server层
- server拿到数据后,对数据进行修改
- 调用存储引擎,记录到buffer pool
- Redo Log 、Undo Log 记录
- 事务提交
Mysql为什么使用B+数做为索引
- B+树能显著减少IO次数,提高效率
- B+得查询效率更稳定,因为数据都在叶子节点
- B+那能提高范围查询的效率,因为叶子节点是双向链接的
- B+采取顺序读取
线程池
线程池的参数
核心线程数
线程池最终保留的线程数
最大线程数
线程池允许的最大线程数,当工作队列满了之后,可以创建的最大线程数
线程存活保留时间
线程结束任务之后保留的时间
存活时间单位
当线程池的当前线程,大于核心线程,那么线程的空闲时间,大于设置存活时间会被销毁
工作队列
线程池核心线程数量满了,来的任务存入工作队列中排队等待
线程池工厂
用于创建新的线程
拒绝策略
核心线程数+任务队列满了,来的任务做的策略
设置线程池参数
核心线程数
这个是要分业务类型的,分以下几种类型:
- CPU密集型
- IO密集型
- 混合类型(CPU密集和IO密集都有)
什么是CPU密集呢?涉及到计算或者数据转换等等,不涉及到阻塞得情况,就是CPU密集。那么如何设置核心线程数呢,可以设置CPU核心数+-1。
什么是IO密集呢?涉及到查询数据、对接第三方接口的这种IO操作,涉及到阻塞就是IO密集型,这个如何设置呢?貌似没有公式
什么是混合类型呢?就是CPU密集和IO密集都有,这个好像也没有公式
其实最终线程池的核心线程数的设置,是要经过压测的,举个例子,我要设置CPU密集的线程池,那么我的核心线程数设置为CPU核心+1,然后进行压测,然后动态的调整核心线程数量,慢慢的压测看处理时间,最终选择一个适合的数量。
总结就是先估一个值,在压测,最终选择一个适合的数量。
最大线程数
理论上设置和核心线程数一样的,就是核心线程数=最大线程数。为什么呢?因为我们的核心线程数理论上设置了最优的线程数量,没必要在多设置工作线程了。
工作队列
这个是要结合业务去设置,要预估我处理一个工作线程要多长时间,在预估可能会有几个工作的数量,或者这样思路,我这个任务可以容忍最大的时间处理。
拒绝策略
总共有四种拒绝策略
- 直接抛异常
- 不处理
- 让主线程去执行,就是工作队列满了之后,到拒绝策略的方法了,直接去把任务执行掉
- 删除掉旧任务,插入新的工作,因为工作队列是一个链表,当核心线程满了之后,就往工作队列插入任务(Runable),每次都是往后插,当工作队列满了之后,就把前面的删除掉,继续尝试插入工作队列
线程池的工作流程
- 判断核心线程是否空闲,如果空闲执行任务
- 如果核心线程满了,插入工作队列
- 工作队列满了之后,判断当前线程池的工作线程,是否大于设置的线程池最大线程,如果不大于,新创建线程执行任务
- 如果线程池的工作线程大于最大线程,那就执行拒绝策略
拒绝策略
拒绝策略分4种
- 直接抛异常
- 工作队列满了,直接抛一个异常,这个工作也不要了
- 不处理
- 什么都不干,这个工作不要了
- 让主线程去执行,就是工作队列满了之后,到拒绝策略的方法了,直接去把任务执行掉
- 工作队列满了,走到拒绝策略,那我直接把任务给干了,不用线程池的线程了。
- 删除掉旧任务,插入新的工作,因为工作队列是一个链表,当核心线程满了之后,就往工作队列插入任务(Runable),每次都是往后插,当工作队列满了之后,就把前面的删除掉,继续尝试插入工作队列
- 这个就是删除老了插入新的任务
拒绝策略根据具体的类型去选择,当我的任务是记录日志这些东西,我认为这些日志可能不重要那就直接扔了。
当我的任务很重要的时候,那我可以把这些任务给序列化,或者丢给MQ去执行,就是留痕,实在不行让主线程去执行
